一些常見的Pandas視覺化圖表操作教程

今天簡單介紹一下Pandas視覺化圖表的一些操作,Pandas其實提供了一個繪圖方法plot(),可以很方便的將Series和Dataframe型別資料直接進行資料視覺化。
1. 概述
這裡我們引入需要用到的庫,並做一些基礎設定。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt# 設定 視覺化風格
plt.style.use(‘tableau-colorblind10’)# 以下程式碼從全域性設定字型為SimHei(黑體),解決顯示中文問題【Windows】
plt.rcParams[‘font.sans-serif’] = [‘SimHei’]# 解決中文字型下座標軸負數的負號顯示問題
plt.rcParams[‘axes.unicode_minus’] = False
plot方法預設是折線圖,而它還支援以下幾類圖表型別:
‘line’ : 折線圖 (default)
‘bar’ : 柱狀圖
‘barh’ : 條形圖
‘hist’ : 直方圖
‘box’ : 箱型圖
‘kde’ : 密度圖
‘density’ : 同密度圖
‘area’ : 面積圖
‘pie’ : 餅圖
‘scatter’ : 散點圖 (DataFrame only)
‘hexbin’ : 六邊形箱體圖 (DataFrame only)
# 隨機種子
np.random.seed(1)
ts = pd.Series(np.random.randn(100), index=pd.date_range(“1/1/2020”, periods=100))
ts = ts.cumsum()
ts.plot()
2. 圖表元素設定
圖表元素設定主要是指 資料來源選擇、圖大小、標題、座標軸文字、圖例、網格線、圖顏色、字型大小、線條樣式、色系、多子圖、圖形疊加與繪圖引擎等等。
資料來源選擇
這裡是指座標軸的x、y軸資料,對於Series型別資料來說其索引就是x軸,y軸則是具體的值;對於Dataframe型別資料來說,其索引同樣是x軸的值,y軸預設為全部,不過可以進行指定選擇。
# 隨機種子
np.random.seed(1)
df = pd.DataFrame(np.random.randn(100, 4), index=ts.index, columns=list(“ABCD”))
df = df.cumsum()
df.head()
對於案例資料,直接繪圖效果如下(顯示全部列)
df.plot()
我們可以指定資料來源,比如指定列A的資料
df.plot(y=’A’)
我們還可以指定x軸和多列為y,我這裡先構建一列X,然後進行資料來源選取
df[“X”] = list(range(len(df)))
df.head()
選擇X列為x軸,B、C列為y軸資料
# 指定多個Y
df.plot(x=’X’,y=[‘B’,’C’])
圖大小
透過引數figsize傳入一個元組,指定圖的長寬(英寸)
注意:以下我們以柱狀圖為例做演示
np.random.seed(1)
df = pd.DataFrame(np.random.rand(10, 3), columns=[“a”, “b”, “c”])
df.head()
# 圖大小
df.plot.bar(figsize=(10,5))
除了在繪圖時定義影象大小外,我們還可以透過matplotlib的全域性引數設定影象大小
plt.rcParams[‘figure.figsize’] = (10,5)標題
透過引數title設定圖表標題,需要注意的是如果想要顯示中文,需要提前設定相關字型引數,參考此前推文《詳解Matplotlib中文字元顯示問題》
# 標題
df.plot.bar(title=’標題’,)
圖例
透過引數legend可以設定圖例,預設是顯示圖例的,可以不顯示或者顯示的圖例順序倒序
# 圖例不顯示
df.plot.bar(legend=False)
# 圖例倒序
df.plot.bar(legend=’reverse’)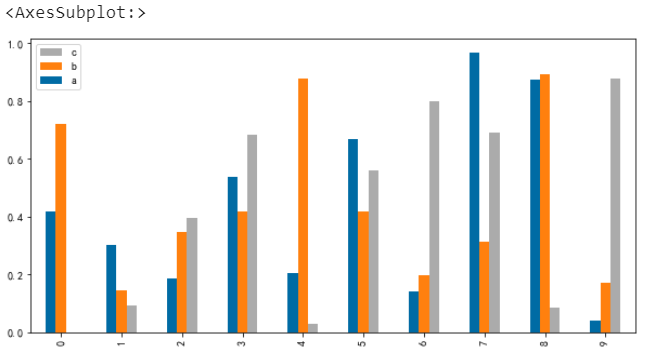
座標軸文字
細心的朋友可能會發現,在上圖中x軸標籤數字顯示是躺著的,怎麼坐起來呢?
那麼可以透過引數rot設定文字的角度
# x軸標籤旋轉角度
df.plot.bar(rot=0)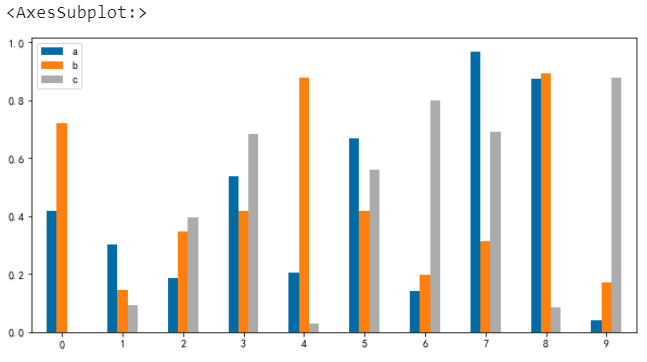
網格線
預設情況下圖表是不顯示網格線的,我們可以透過引數grid來設定其顯隱
# 網格線
df.plot.bar(grid=True)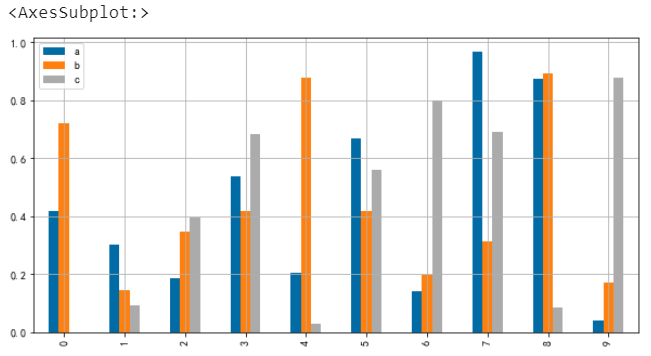
圖顏色
透過color引數可以設定填充顏色,edgecolor可以設定邊框顏色
# 指定顏色
df.plot.bar(color=[‘red’,’orange’,’yellow’], edgecolor=’grey’)字型大小
透過fontsize可以設定字型大小
# 字型大小
df.plot.bar(fontsize=20)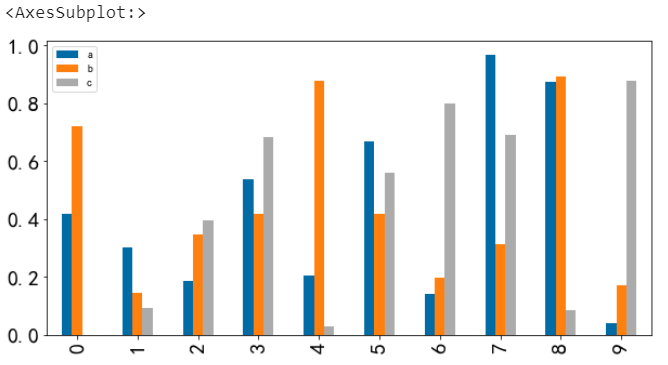
線條樣式
對於折線圖來說,還可以設定線條樣式style
df.plot(style = [‘.-’,’ — ‘,’*-’] # 圓點、虛線、星星
)
色系
透過colormap引數可以指定色系,色系選擇可以參考matplotlib庫的色系表
# 指定色系
x = df.plot.bar(colormap=’rainbow’)
多子圖
透過subplots引數決定是否以多子圖形式輸出顯示圖表
# 多子圖
x = df.plot.line(title =’多子圖’,
fontsize =16,
subplots =True, # 分列
style = [‘.-’,’ — ‘,’*-’,’^-’] # 圓點、虛線、星星
)
影象疊加
不同的圖表型別組合在一起
df.a.plot.bar()
df.b.plot(color=’r’)
繪圖引擎
透過backend可以指定不同的繪圖引擎,目前預設是matplotlib,還支援bokeh、plotly、Altair等等。當然,在使用新的引擎前需要先安裝對應的庫。
# 繪圖引擎
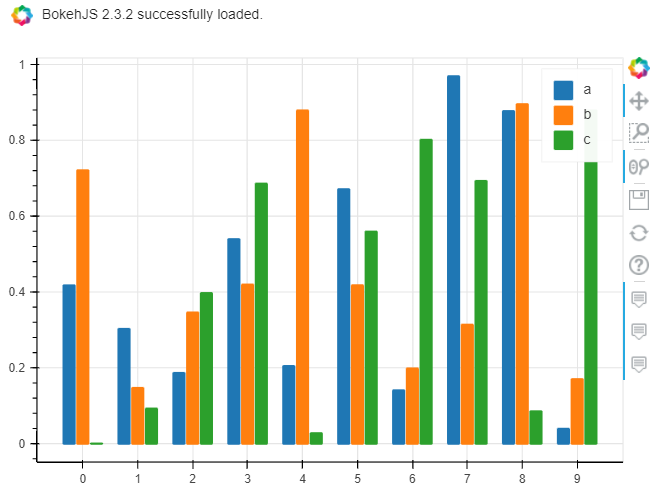
import pandas_bokehpandas_bokeh.output_notebook()
df.plot.bar(backend=’pandas_bokeh’)
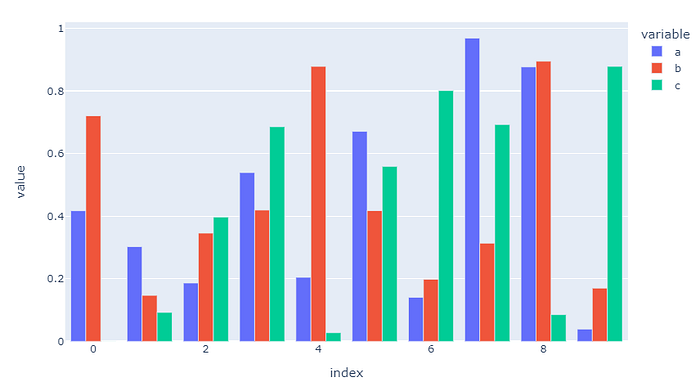
# 繪圖引擎 plotly
df.plot.bar(backend=’plotly’,
barmode=’group’,
height=500, # 圖表高度
width=800, # 圖表寬度
)
3. 常見圖表型別
在介紹完圖表元素設定後,我們演示一下常見的幾種圖表型別。
柱狀圖
柱狀圖主要用於資料的對比,透過柱形的高低來表達資料的大小。
# 柱狀圖bar
df.plot.bar()(這裡不做展示,前面案例中有)
此外我們還可以繪製堆疊柱狀圖,透過設定引數stacked來搞定
# 堆疊柱狀圖
df.plot.bar(stacked=True)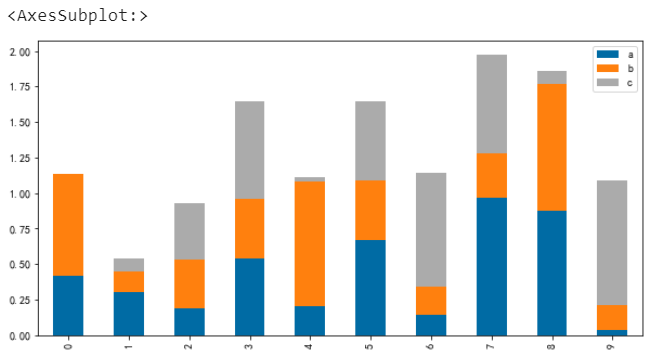
柱狀圖多子圖
# 柱狀圖多子圖
df.plot.bar(subplots=True, rot=0)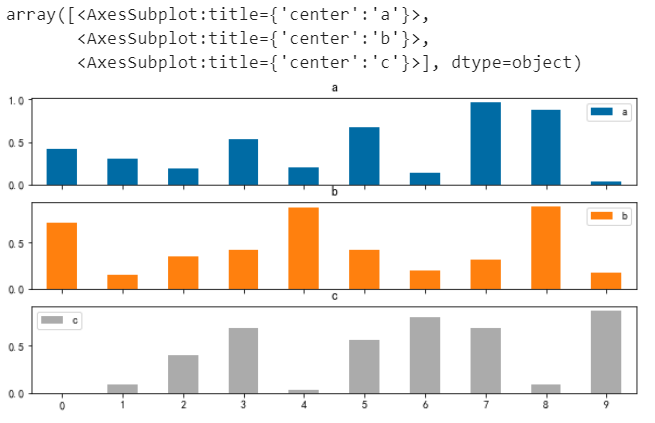
條形圖
條形圖和柱狀圖其實差不多,條形圖就是柱狀圖的橫向展示
# 條形圖barh
df.plot.barh(figsize=(6,8))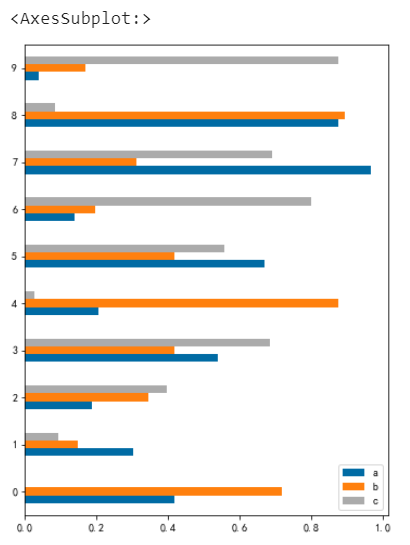
堆疊條形圖
# 堆疊條形圖
df.plot.barh(stacked=True)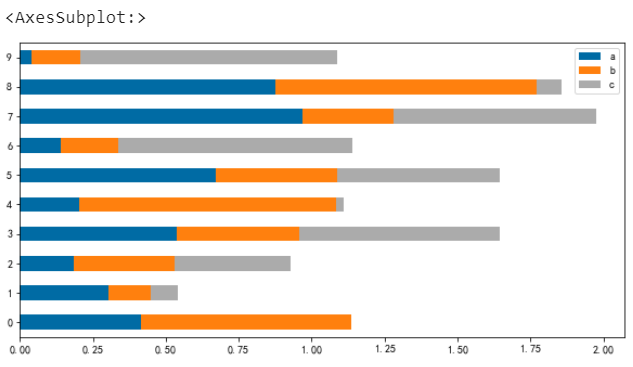
直方圖
直方圖又稱為質量分佈圖,主要用於描述資料在不同區間內的分佈情況,描述的資料量一般比較大。
# 直方圖
np.random.seed(1)
df = pd.DataFrame(
{
“a”: np.random.randn(1000) + 1,
“b”: np.random.randn(1000),
“c”: np.random.randn(1000) — 1,
},
columns=[“a”, “b”, “c”],
)
df.head()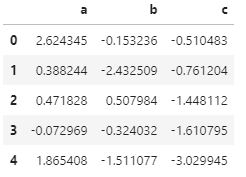
df.plot.hist(alpha=0.5) # alpha設定透明度
單直方圖
# 單直方圖
df.a.plot.hist()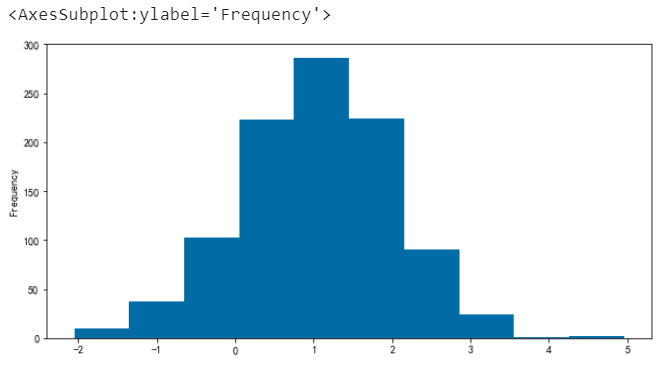
堆疊並指定分箱數(預設為 10)
# 堆疊並指定分箱數(預設為 10)
df.plot.hist(stacked=True, bins=20)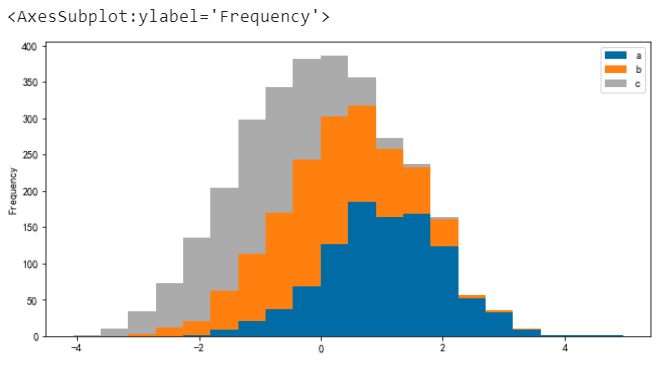
橫向展示
# 可以透過orientation=’horizontal’和 cumulative=True 繪製橫向和累積直方圖
df[“a”].plot.hist(orientation=”horizontal”, cumulative=True)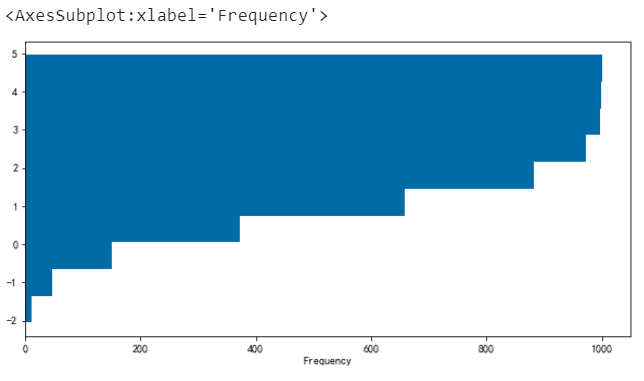
多子圖展示
# 繪製多子圖
df.hist(color=”k”, alpha=0.5, bins=50)
單個直方圖(自定義分箱+透明度)
# 以下2種方式效果一致
df.hist(‘a’, bins = 20, alpha=0.5)
# df.a.hist(bins = 20, alpha=0.5)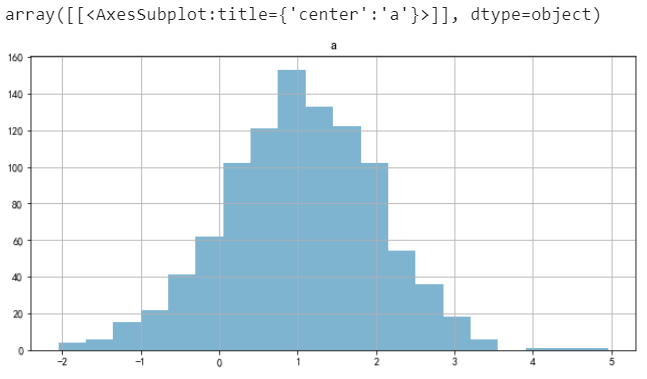
分組
# by 分組
np.random.seed(1)
data = pd.Series(np.random.randn(1000))
data.hist(by=np.random.randint(0, 4, 1000), figsize=(6, 4))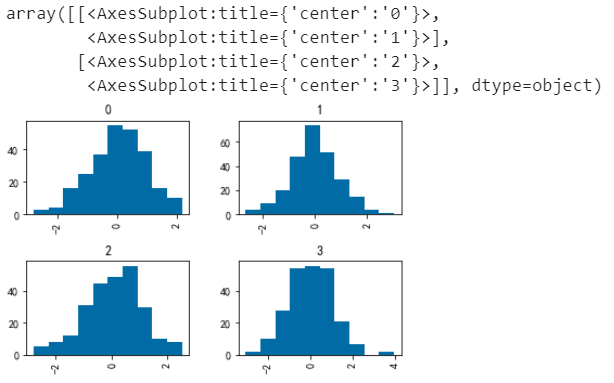
箱線圖
箱線圖又稱盒須圖、箱型圖等,用於顯示一組資料分佈情況的統計圖。
np.random.seed(1)
df = pd.DataFrame(np.random.rand(10, 5), columns=[“A”, “B”, “C”, “D”, “E”])
df.head()
df.boxplot()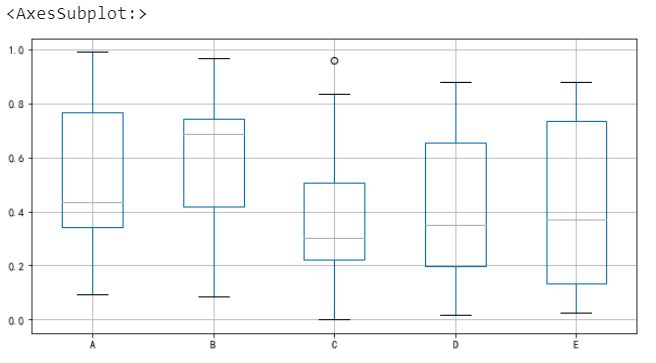
指定元素顏色
# 指定元素顏色
color = {
“boxes”: “Green”, # 箱體顏色
“whiskers”: “Orange”, # 連線顏色
“medians”: “Blue”, # 中位數顏色
“caps”: “Gray”, # 極值顏色
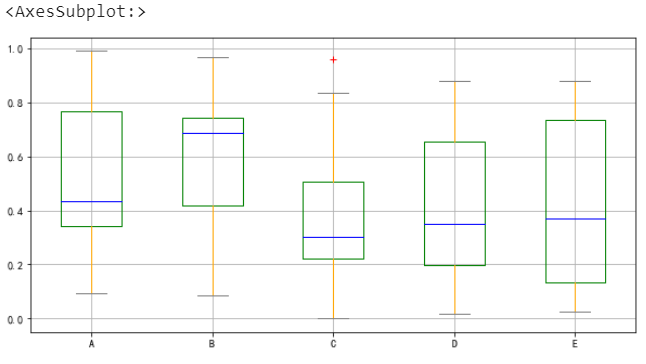
}df.boxplot(color=color, sym=”r+”)
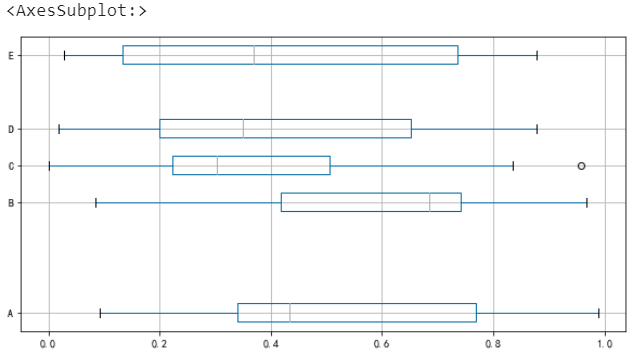
橫向展示
df.boxplot(vert=False, positions=[1, 4, 5, 6, 8])
面積圖
面積圖又稱區域圖,是將折線圖與座標軸之間的區域使用顏色填充,填充顏色可以很好地突出趨勢資訊,一般顏色帶有透明度會更合適於觀察不同序列之間的重疊關係。
np.random.seed(1)
df = pd.DataFrame(np.random.rand(10, 4), columns=[“a”, “b”, “c”, “d”])
df.head()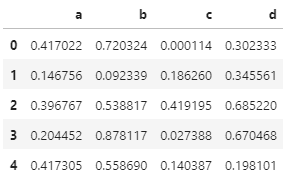
預設情況下,面積圖是堆疊的
# 預設是堆疊
df.plot.area()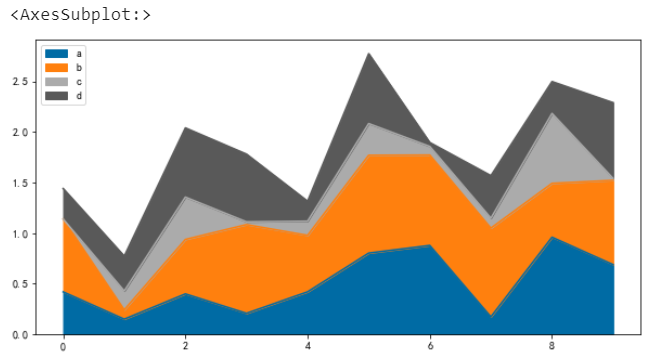
單個面積圖
df.a.plot.area()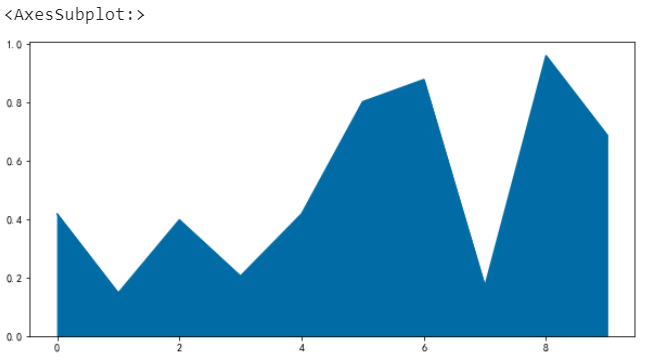
取消堆疊
# 取消堆疊
df.plot.area(stacked=False)
散點圖
散點圖就是將資料點展示在直角座標系上,可以很好地反應變數之間的相互影響程度
np.random.seed(1)
df = pd.DataFrame(np.random.rand(50, 4), columns=[“a”, “b”, “c”, “d”])df[“species”] = pd.Categorical(
[“setosa”] * 20 + [“versicolor”] * 20 + [“virginica”] * 10
)df.head()
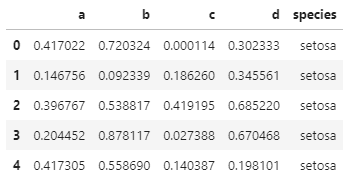
指定一組資料
df.plot.scatter(x=”a”, y=”b”)
多組資料並用不同顏色標註
ax = df.plot.scatter(x=”a”, y=”b”, color=”Blue”, label=”Group 1")
df.plot.scatter(x=”c”, y=”d”, color=”red”, label=”Group 2", ax=ax)
一組資料,x/y及z,其中x/y表示位置、z的值用於顏色區分
df.plot.scatter(x=”a”, y=”b”, c=”c”, s=50) # 引數s代表散點大小
一組資料,然後分類並用不同顏色(色系下)表示
df.plot.scatter(x=”a”, y=”b”, c=”species”, cmap=”viridis”, s=50)
氣泡圖
df.plot.scatter(x=”a”, y=”b”, color=”red”, s=df[“c”] * 200)
餅圖
餅圖主要用於不同分類的資料佔總體的比例情況
np.random.seed(8)
series = pd.Series(3 * np.random.rand(4), index=[“a”, “b”, “c”, “d”], name=”series”)
series
series.plot.pie(figsize=(6, 6), fontsize=20)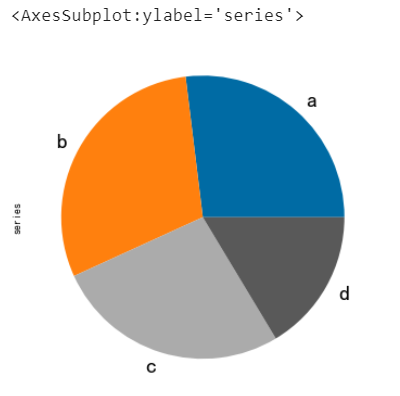
多子圖展示
np.random.seed(8)
df = pd.DataFrame(
3 * np.random.rand(4, 2), index=[“a”, “b”, “c”, “d”], columns=[“x”, “y”]
)
df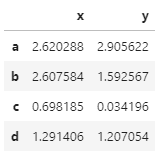
df.plot.pie(subplots=True, figsize=(8, 4), fontsize=16)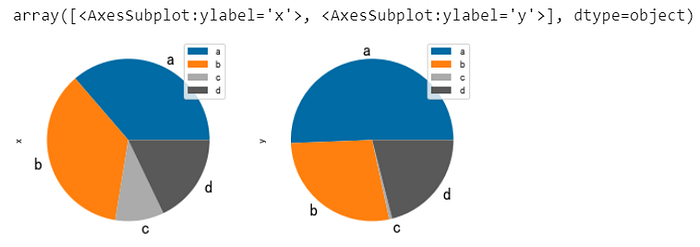
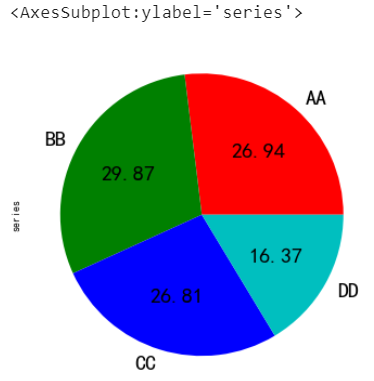
指定顯示樣式
series.plot.pie(
labels=[“AA”, “BB”, “CC”, “DD”], # 標籤
colors=[“r”, “g”, “b”, “c”], # 指定顏色
autopct=”%.2f”, # 數字格式(百分比)
fontsize=20,
figsize=(6, 6),
)
如果資料總和小於1,可以繪製扇形
series = pd.Series([0.1] * 4, index=[“a”, “b”, “c”, “d”], name=”series2")
series.plot.pie(figsize=(6, 6), normalize=False)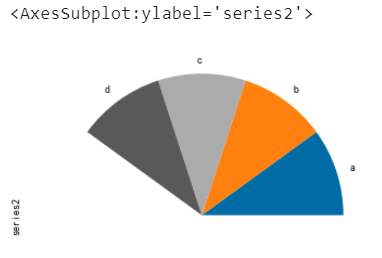
4. 其他圖表型別
在常見圖表中,有密度圖和六邊形箱型圖 繪製過程報錯,暫時沒有解決(本機環境:pandas1.3.1)
本節主要介紹散點矩形圖、安德魯曲線等,更多資料大家可以查閱官方文件瞭解
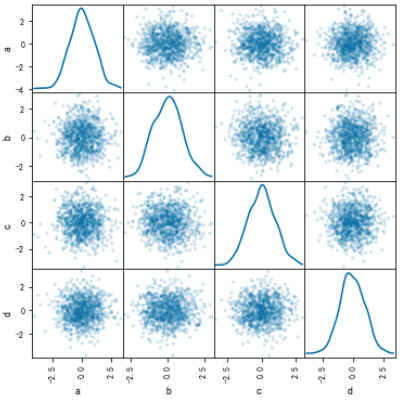
散點矩形圖
from pandas.plotting import scatter_matrixdf = pd.DataFrame(np.random.randn(1000, 4), columns=[“a”, “b”, “c”, “d”])
scatter_matrix(df, alpha=0.2, figsize=(6, 6), diagonal=”kde”)
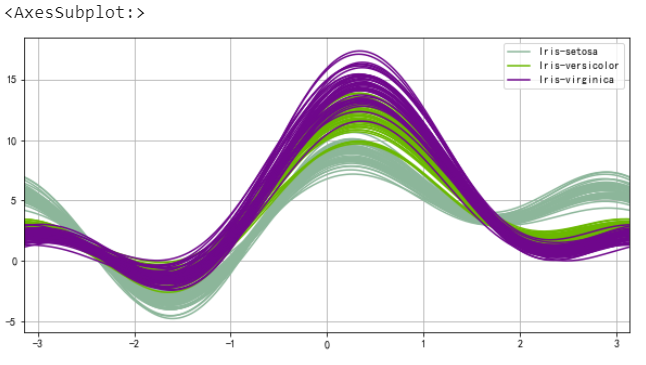
安德魯曲線
from pandas.plotting import andrews_curvesdata = pd.read_csv(“iris.csv”)
andrews_curves(data, “Name”)
以上就是本次全部內容。
文章來自公眾號「可以叫我才哥」
地址:https://mp.weixin.qq.com/s/goOXo1ey9NXHR-frRTPXfw

文章推選
●乾貨攻略|Python資料視覺化攻略大全,8000字超詳細!
●10張架構圖包含Python所有方向的學習路線,你們要的體系全在這

我是「數據分析那些事」。常年分享數據分析乾貨,不定期分享好用的職場技能工具。各位也可以關注我的Facebook,按讚我的臉書並私訊「10」,送你十週入門數據分析電子書唷!期待你與我互動起來~
